tran·scrip·tion/ˌ tran(t)ˈskripSH(ə)n/
a written or printed representation of something.
Written representation of audio is normally considered as transcription. How does one go from audio to written word? We could listen to the audio word by word and note down the written representation of each word. This is a manual process and sometimes, we may need to pause the audio to catch up. Some words might be transcribed incorrectly.
Can AI help speed up the process and reduce errors in transcription? That’s a rhetorical question because AI already does this to some extent, we have seen it in products from Apple, Amazon, Google and others.
What would it take for a machine to listen and convert that listening into written word? In its simplest sense, assuming that the machine knows the entire vocabulary of that language in which the audio is in e.g. English, it can compare the spoken word with its vast library of phonemes to figure out what word the audio maps to and “type’ that word in that language into a text editor. Repeating this process for every uttered word recursively will produce a text document that is (hopefully) an exact representation of the audio.
For example, the spoken word “Potato” could be recognized as such by the software that processes each phoneme in the word with the library of phonemes and deconstruct the word to its basic phonemes, then match the possible word with a library of words, take context into consideration and figure out if it the textual representation of the spoken audio is really “Pohtahtoh” or “Pahtayto” or something else.
Apparently, most speech recognition systems use something called Hidden Markov Models.


Can you implement a speech recognition and transcription system for Telugu language, using off the shelf libraries? This is a question I don’t know the answer to but let’s find out.
I set out looking for speech recognition libraries already available I can leverage and found a few. I don’t know which one is best suited for my purpose. I ‘ll with Google Cloud Speech to Text API as it claims to support 120 languages and Telugu is one of them.
I uploaded a Telugu song clip and Google STT produced the following –
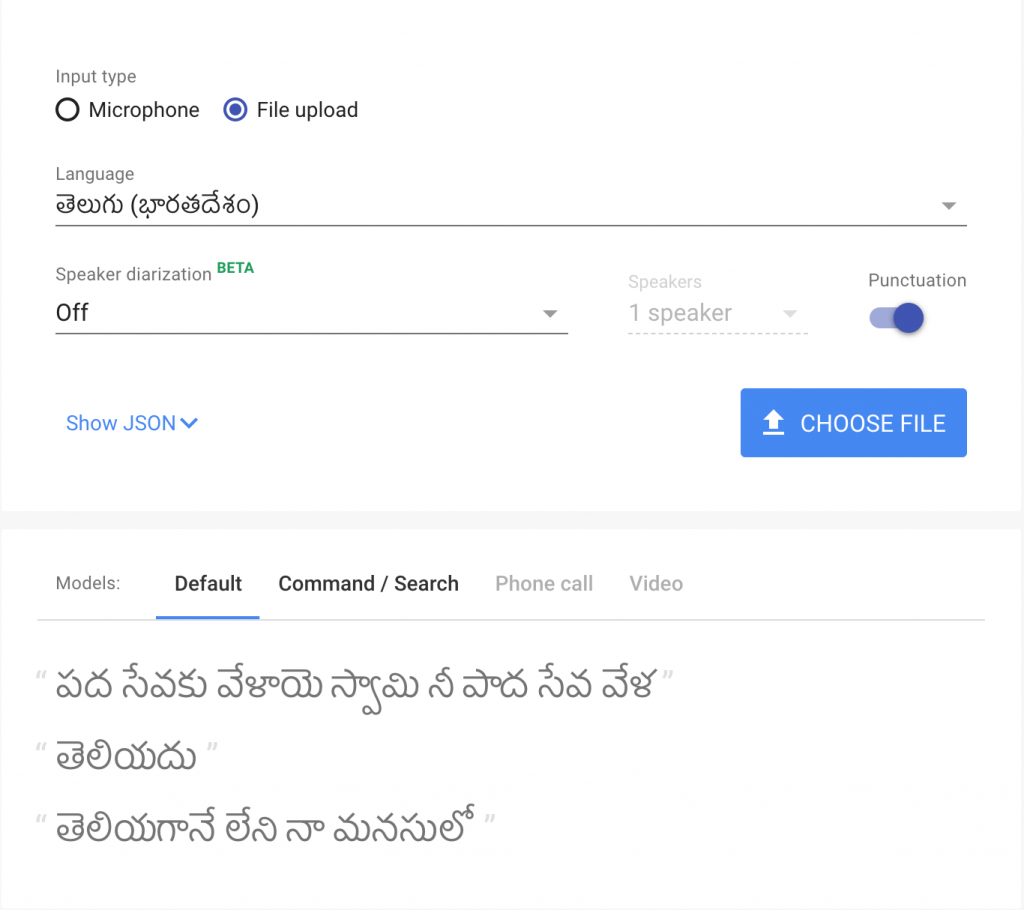
The lines go –
Nee Pada Sevaku Velaye Swami Aapada Baapava Aananda Nilaya Daari Tennu Teliyaga Leni Daasula Brovaga Vegame Raava
Google transcribed that to –
Pada Sevaku Velaye Swami, Nee Pada Seva Vela Teliyadu Teliyagaane Leni Naa Manasulo
What just happened. Why did Google transcription not work? In fact, it is so far off, the transcribed text reads like gibberish.
It’s possible the audio was not of great quality. It’s also possible that the Telugu vocabulary universe of Google Speech-to-Text System (GSTT) is limited. Perhaps the words Aapada, Baapava, Aananda, Nilaya, Daari, Tennu and others are not transcribed properly because related phonemes are missing from the GSTT.
Can one add phonemes and new words to GSTT to improve its accuracy? Funny thing is, it’s possible to add vocabulary to GSTT, it’s simple but not easy. It requires you to know programming and using Google’s STT Application Programming Interface (API). We will look at how to improve Google’s Speech to Text system by adding to its vocabulary in Part 2!