Can a developer enhance Google’s Speech to Text system (GS2T)? Short answer is “Yes”. Let’s take a look how to go about it
Google has what’s called language “hints”. By adding hints to the vocabulary, google speech-to-text is able to “understand” the audio and transcribe better.
As I had shared in part 1 of this blog, I tried transcribing the following
The lines in English and Telugu –
Nee Pada Sevaku Velaye Swami Aapada Baapava Aananda Nilaya Daari Tennu Teliyaga Leni Daasula Brovaga Vegame Raava నీ పద సేవకు వేళాయె స్వామి ఆపద బాపవా ఆనంద నిలయ దారి తెన్నూ తెలియగ లేని దాసుల బ్రోవగ వేగమే రావా
Google transcribed that to –
Pada Sevaku Velaye Swami, Nee Pada Seva Vela Teliyadu Teliyagaane Leni Naa Manasulo పద సేవకు వేళాయె స్వామి, నీ పాద సేవ వేళ తెలియదు తెలియగానే లేని నా మనసులో
I’d like to help Google’s S2T to transcribe better by providing the words (Aapada, Baapava, Aananda, Nilaya, Daari, Tennu) as “phrase hints”. Once I do that, I will transcribe again and hope that something better comes out the other end this time.
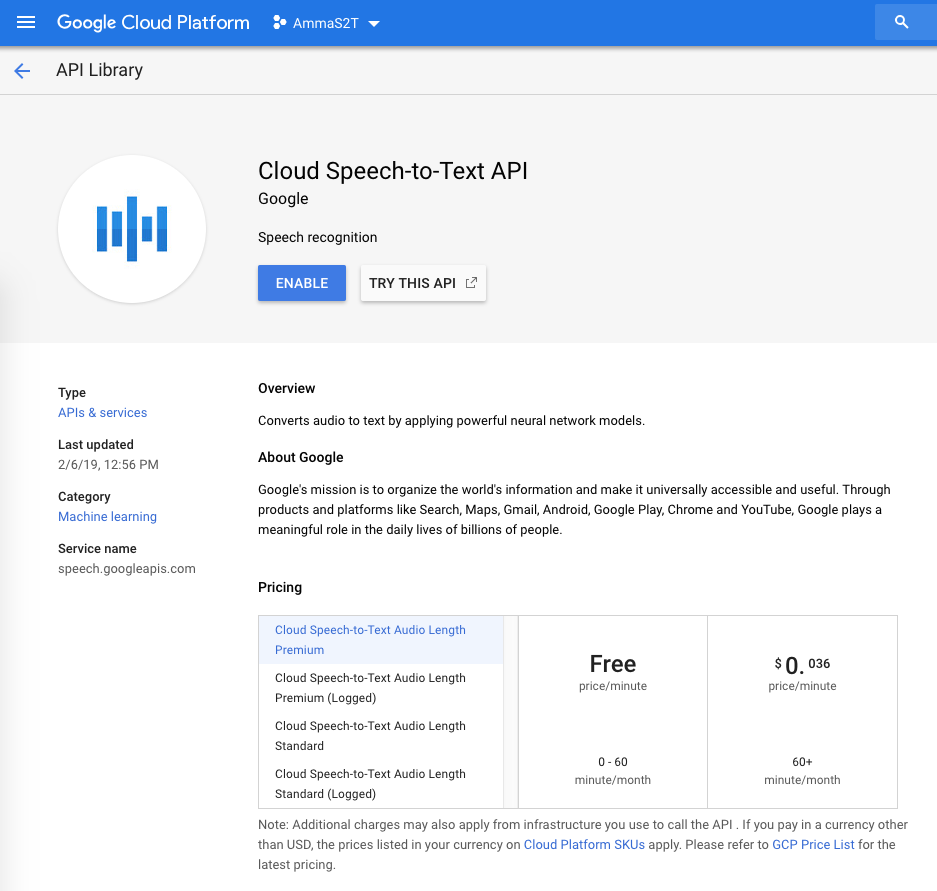
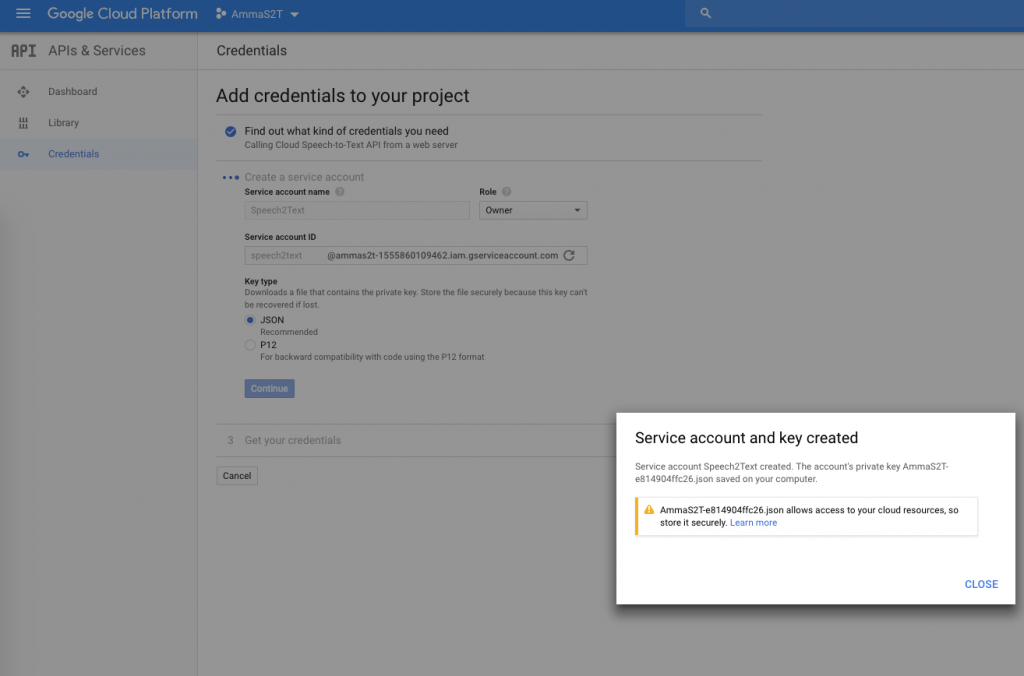
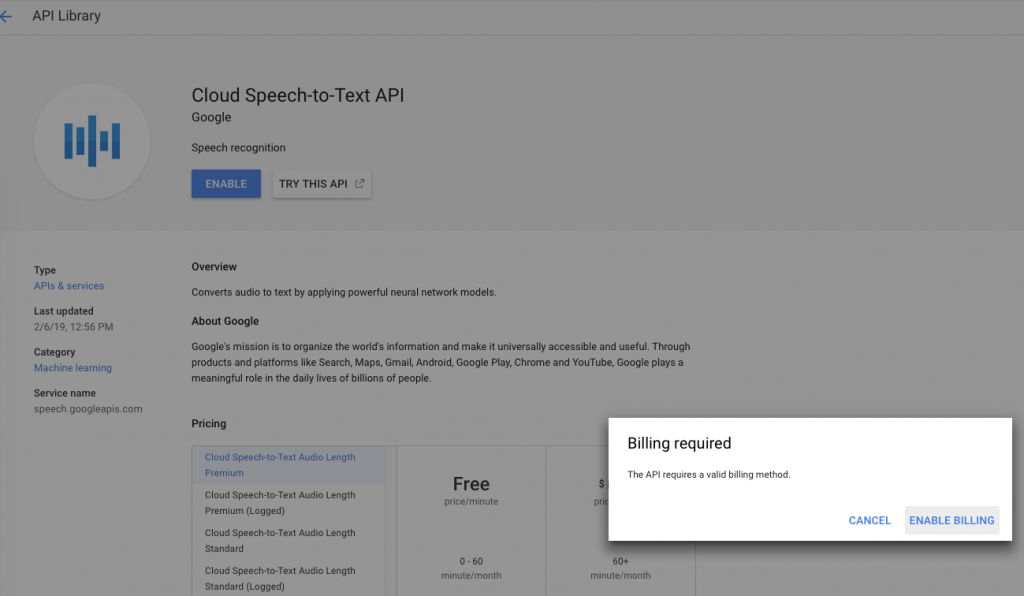
In order to get my phrase hints across to GS2T I need to enroll as a Google Cloud Platform developer, create an account and enable Cloud Speech-To-Text APIs and write a bit of json code to get going. There are good examples in Google cloud documentation
Here is how I fed GS2T my phrase hints
curl -X POST \
-H "Authorization: Bearer "$(gcloud auth application-default print-access-token) \
-H "Content-Type: application/json; charset=utf-8" --data \
"{ 'config': { \
'language_code': 'te-IN', \
'speechContexts': { \
"phrases":['దారి','తెన్నూ', 'తెలియక', 'లేని', 'ఆపద', 'బాపవా'] \
} \
}, \
'audio' : { \
'uri':'gs://ammas2t/12465.flac' \
} \
}" "https://speech.googleapis.com/v1/speech:longrunningrecognize"$ ./resultcurlcmd
{
"name": "4980738099736676025",
"metadata": {
"@type": "type.googleapis.com/google.cloud.speech.v1.LongRunningRecognizeMetadata",
"progressPercent": 100,
"startTime": "2019-04-22T20:05:40.740461Z",
"lastUpdateTime": "2019-04-22T20:06:41.100358Z"
},
"done": true,
"response": {
"@type": "type.googleapis.com/google.cloud.speech.v1.LongRunningRecognizeResponse",
"results": [
{
"alternatives": [
{
"transcript": "పద సేవకు వేళాయె నీ పదసేవ వేళాయె",
"confidence": 0.6822279
}
]
},
{
"alternatives": [
{
"transcript": "తెలియక లేని నా",
"confidence": 0.6823187
}
]
},
{
"alternatives": [
{
"transcript": " మమ్మేలుకో చరణములే నమ్మితి నీ పదసేవ వేళలో స్వామి",
"confidence": 0.5497838
}
]
},
{
"alternatives": [
{
"transcript": " ఆనంద నిలయం",
"confidence": 0.63640434
}
]
},
{
"alternatives": [
{
"transcript": " ఆశల జీవితం",
"confidence": 0.3930311
}
]
},
{
"alternatives": [
{
"transcript": " లేని జీవితం",
"confidence": 0.613313
}
]
},
{
"alternatives": [
{
"transcript": " నేను",
"confidence": 0.41449854
}
]
},
{
"alternatives": [
{
"transcript": " హాయ్ బ్రదర్",
"confidence": 0.59204257
}
]
}
]
}
}The transcription seems to have gone south for some reason. I need to investigate further why my phrase hints not only didn’t help make the result better but they made it worse.
If you want to follow along how I setup Google Cloud Speech-To-Text API here are the screenshots, mostly self-evident.
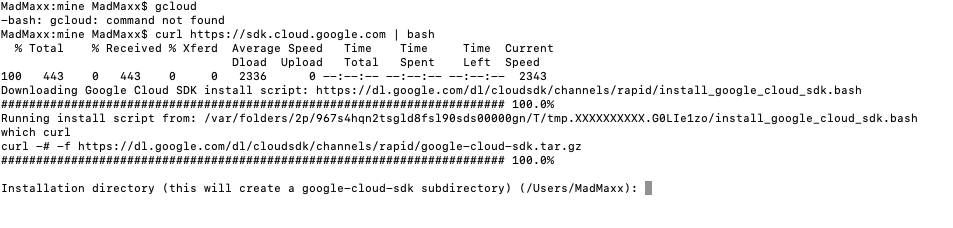

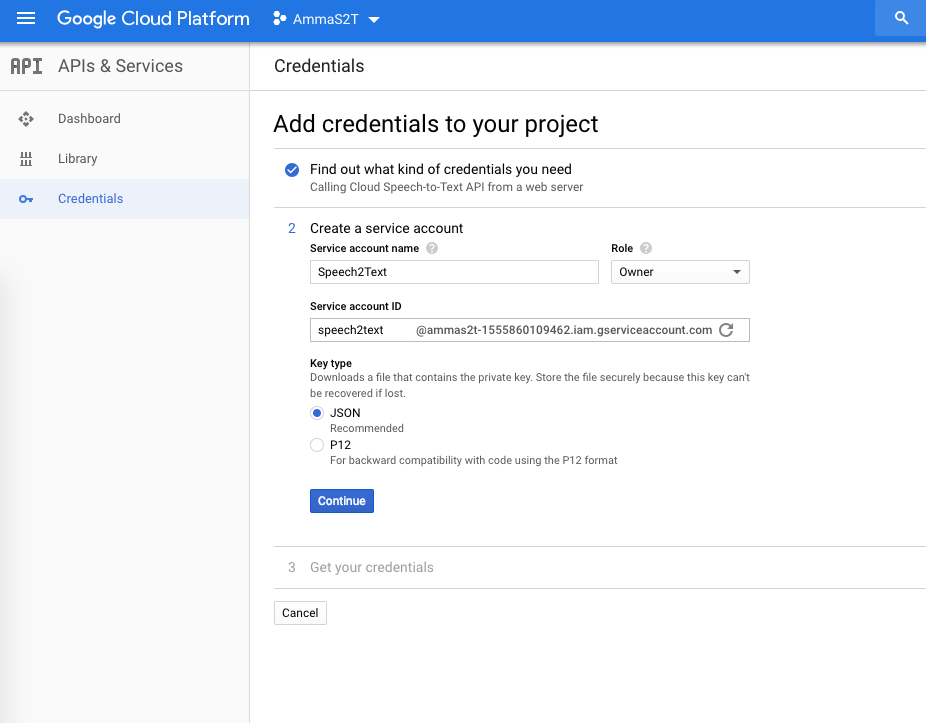
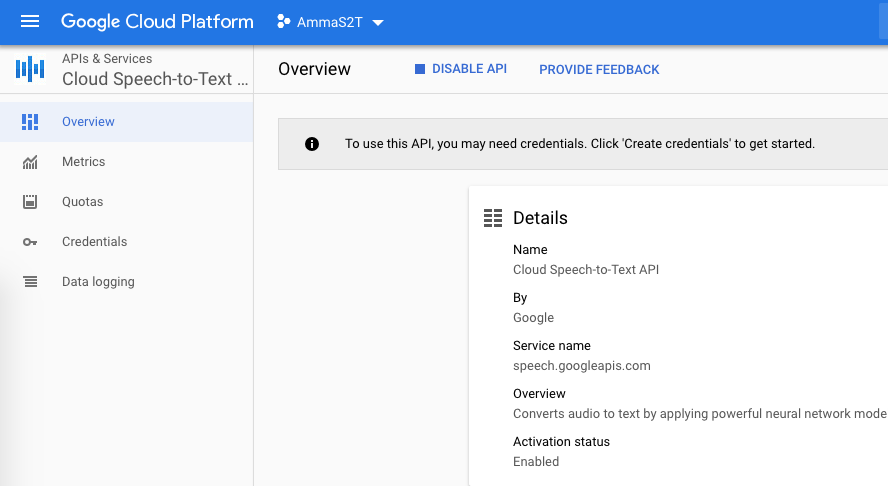
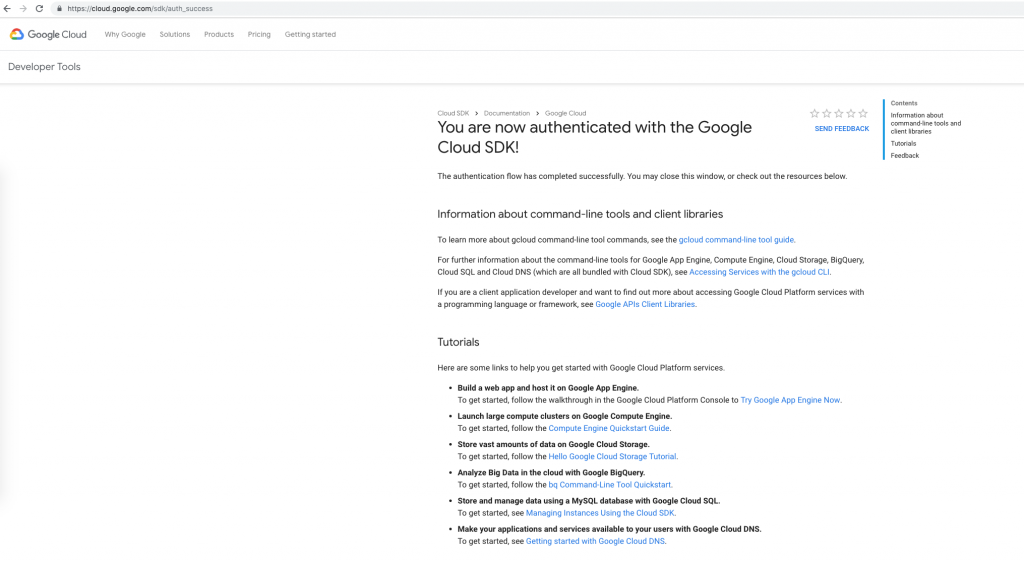
Then download and install GCloud SDK and tools
